1.1.引言
InnoDB是能够保证事务安全的MySQL存储引擎。主要特点是:
- 支持行锁;
- 支持MVCC;
- 支持外键;
- 提供一致性非锁定读;
- 被设计用来有效利用以及使用内存和CPU;
1.2.架构图
InnoDB 的架构分为两块:内存中的结构和磁盘上的结构。InnoDB 使用日志先行策略,将数据修改先在内存中完成,并且将事务记录成重做日志(Redo Log),转换为顺序IO高效的提交事务。
这里日志先行,说的是日志记录到数据库以后,对应的事务就可以返回给用户,表示事务完成。但是实际上,这个数据可能还只在内存中修改完,并没有刷到磁盘上去。内存是易失的,如果在数据落地前,机器挂了,那么这部分数据就丢失了。
InnoDB 通过 redo 日志来保证数据的一致性。如果保存所有的重做日志,显然可以在系统崩溃时根据日志重建数据。
当然记录所有的重做日志不太现实,所以 InnoDB 引入了检查点机制。即定期检查,保证检查点之前的日志都已经写到磁盘,则下次恢复只需要从检查点开始。
1.3.InnoDB 内存中的结构
Buffer Pool,Change Buffer、Adaptive Hash Index以及 Log Buffer
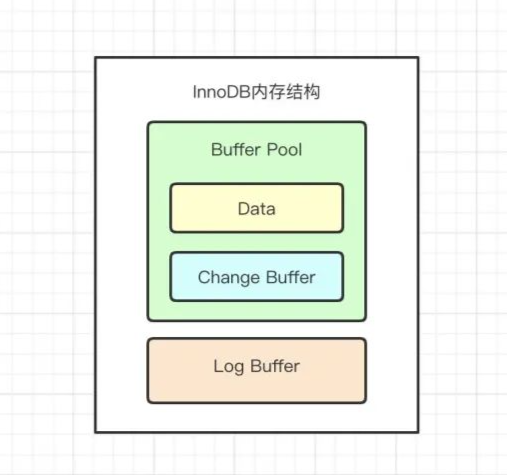
Buffer Pool
作用:为了加快数据的访问,会把常用的数据放在缓存中,避免每次都去访问数据库。
InnoDB中数据管理的最小单位为页,默认每页大小为16KB
缓冲池缓存的数据包括Page Cache、Change Buffer、Data Dictionary Cache等,通常 MySQL 服务器的 80% 的物理内存会分配给 Buffer Pool。Buffer Pool被分成了很多页,每页可以存放很多数据。那么为什么要分配这么多内存空间呢,因为能缓存的数据就更多,更多的操作都会发生在内存(内存是最快的!!)
多个Buffer Pool
一个mysql实例中,缓冲池不只一个,而是有多个,所有缓存页根据哈希值平均分配到不同缓冲池实例。将内存空间分为多个缓冲池是为了增加临界资源,减少多个线程对buffer pool的竞争(毕竟访问buffer pool的各种链表都需要加锁处理),提高并发。
每个 buffer pool有自己独立的内存空间,独立的lru、free、flush链表。buffer pool的个数不是越多越好,因为管理每一个buffer pool也需要开销。
InnoDB使用了链表来组织页和页中存储的数据,页与页之间形成了双向链表,这样可以方便的从当前页跳到下一页,同时使用LRU(Least Recently Used)算法去淘汰那些不经常使用的数据。
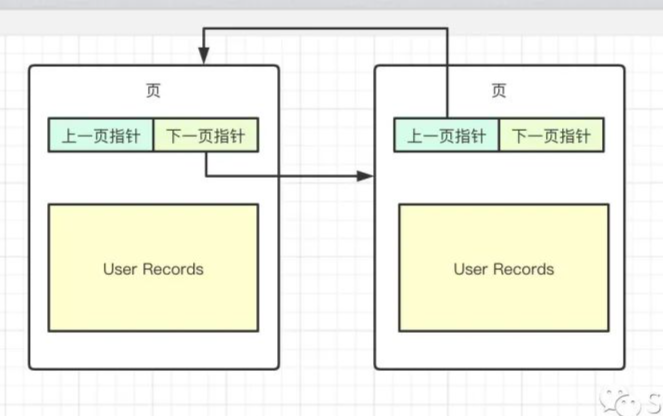
为了提高缓存管理效率,InnoDB的缓存池通过一个页链表实现,很少访问的页会通过缓存池的 LRU 算法淘汰出去。这里不得提到
LRU算法
LRU算法:
普通 : 实现的是末尾淘汰法,当整个链表已满时,淘汰尾部,将新的数据页加入头部
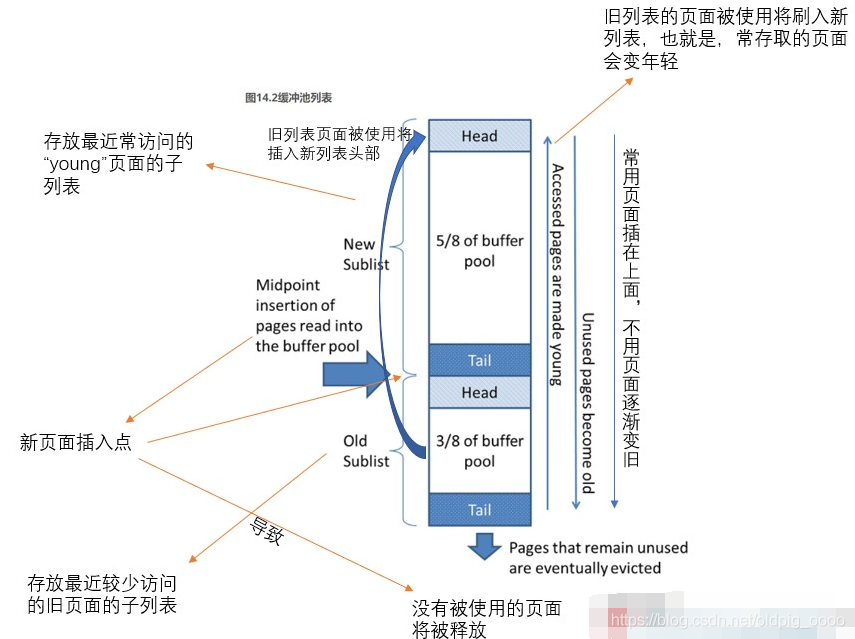
new sublist占用5/8的空间 *‘热端’* 经常被访问的数据
midpoint是两者的中间点
old sublist占用3/8的空间 *‘冷端’* 很少被访问的数据
起到了一个隔断的作用
流程:
1.当 InnoDB 从磁盘读一页数据并放入缓冲池中时,它会将此页插入到列表的中间位置(也就是冷端页子表的头部)。发生读页一般是因为用户查询数据,或者InnoDB自动触发的read-ahead操作。
2.读取旧页子表中的数据会让该页变新(年轻,young),’并将其移动到缓冲池的头部(也就是新页子表的头部)。
3.如果是用户查询读造成该页被读取,则该页会立即被标识为年轻,并直接插入到列表头部。
如果该页因为read-ahead被读取,而是放入列表中点,需要再次读取才能使该页被标识为年轻状态。
read-ahead、或者表、索引扫描都会造成类似的缓冲池扰动。’在这些情景下,页通常会被读取(命中)若干次,然后从此不再访问。
为此MySQL提供了配置参数innodb_old_blocks_time用来指定该页在放入缓冲池后第一次读之后一定时间内(时间窗口,单位毫秒,milliseconds)
读取不会被标识为年轻,也就是不会被移动到列表头部。参数innodb_old_blocks_time的默认值是1000s,增大这个参数将会造成更多的页会更快的从缓冲池中被淘汰。
1s就淘汰
- Buffer Pool 预热
Mysql重启时,BP中的热数据会清空,为此mysql提供了缓冲池预热功能,当关机时会把内存中的热数据写入到 ib_buffer_pool 文件中,保存的数据占 lru 的比例可由参数控制,mysql启动时会自动加载热数据到缓冲池。预热功能默认开启。
MySQL缓冲池污染
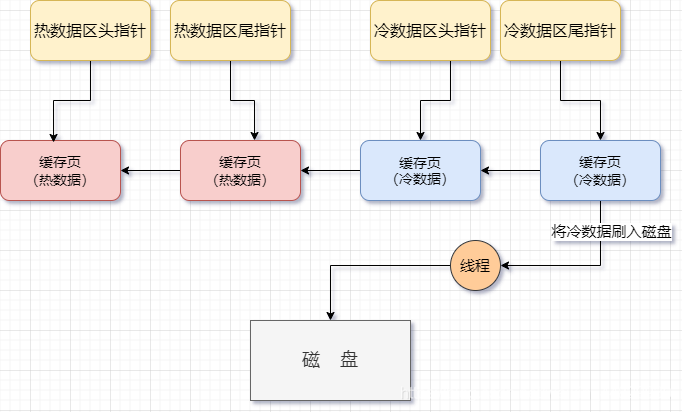
当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
全表扫描 或者查询到一个数量集比较大的数据 如果频繁读写就会把young的部分的数据全部替换出去
所以innodb就采用了young 的和 old 两个分区 大量的数据首先会被插入到old的头部 待的时间需要大于T
才会被放在young区的头部,并淘汰young区不活跃的页
Change Buffer
DML 不会立刻刷入磁盘 而是会先将变更的页写入到缓冲区,经过一系列策略同步到磁盘。
Change buffer 的主要目的是将对 非唯一 辅助索引页的操作缓存下来,以此减少辅助索引的随机IO,并达到操作合并的效果。它会占用部分Buffer Pool 的内存空间。如果辅助索引页已经在缓冲区了,则直接修改即可;如果不在,则先将修改保存到 Change Buffer。Change Buffer的数据在对应辅助索引页读取到缓冲区时合并到真正的辅助索引页中。Change Buffer 内部实现也是使用的 B+ 树。
此时分为两种情况:
1、当更改的页存在于 Buffer Pool 的 lru 链表,则直接在缓冲池中修改这个页,这个页会变成脏页,链入到 flush list中,但并不马上刷盘;此时不涉及 change buffer 操作。
2、当更改的页不存在于 Buffer Pool 的 lru 链表,就要先从磁盘读取要修改的数据页到Buffer Pool后再修改(数据不可能在磁盘中直接更改,肯定要读到内存,在内存中修改)。
但为了避免修改操作引发的磁盘读IO,系统会将DML操作记录到 change buffer中,并不马上刷盘。
等下次对这些修改的页进行查询时,由于lru链表不存在该页,会从磁盘读取(磁盘页是更改前的数据),为了避免读到脏数据,该磁盘页会和 change buffer中的更改合并后才链入到 lru链表。
如果未来一段时间都不会查询到这个修改了的页,也会有 insert buffer thread 定时将change buffer 的数据合并到磁盘页中。
change buffer 默认占 Buffer Pool 的 25%,最大允许占50%。可以根据写业务的量调整,写操作越频繁,change buffer 带来的性能提升越明显。
查看Change Buffer信息
show engine innodb status
Adaptive Hash Index
自适应哈希索引(AHI)查询非常快,一般时间复杂度为 O(1),相比 B+ 树通常要查询 3~4次,效率会有很大提升。innodb 通过观察索引页上的查询次数,如果发现建立哈希索引可以提升查询效率,则会自动建立哈希索引,称之为自适应哈希索引,不需要人工干预,可以通过 innodb_adaptive_hash_index 开启,MySQL5.7 默认开启。
考虑到不同系统的差异,有些系统开启自适应哈希索引可能会导致性能提升不明显,而且为监控索引页查询次数增加了多余的性能损耗, MySQL5.7 更改了 AHI 实现机制,每个 AHI 都分配了专门分区,通过 innodb_adaptive_hash_index_parts配置分区数目,默认是8个
Log Buffer
Log Buffer是 重做日志在内存中的缓冲区,大小由 innodb_log_buffer_size 定义,默认是 16M。一个大的 Log Buffer可以让大事务在提交前不必将日志中途刷到磁盘,可以提高效率。如果你的系统有很多修改很多行记录的大事务,可以增大该值。
配置项 innodb_flush_log_at_trx_commit 用于控制 Log Buffer 如何写入和刷到磁盘。注意,除了 MySQL 的缓冲区,操作系统本身也有内核缓冲区。
默认为1,表示每次事务提交都会将 Log Buffer 写入操作系统缓存,并调用配置的 “flush” 方法将数据写到磁盘。
设置为 1 因为频繁刷磁盘效率会偏低,但是安全性高,最多丢失 1个 事务数据。
而设置为 0 和 2 则可能丢失 1秒以上 的事务数据。
为 0 则表示每秒才将 Log Buffer 写入内核缓冲区并调用 “flush” 方法将数据写到磁盘。
为 2 则是每次事务提交都将 Log Buffer写入内核缓冲区,但是每秒才调用 “flush” 将内核缓冲区的数据刷到磁盘。
innodb_flush_log_at_timeout 可以配置刷新日志缓存到磁盘的频率,默认是1秒。注意刷磁盘的频率并不保证就正好是这个时间,可能因为MySQL的一些操作导致推迟或提前。
而这个 “flush” 方法并不是C标准库的 fflush 方法(fflush是将C标准库的缓冲写到内核缓冲区,并不保证刷到磁盘),它通过 innodb_flush_method 配置的,默认是 fsync,即日志和数据都通过 fsync 系统调用刷到磁盘。
可以发现,InnoDB 基本每秒都会将 Log buffer落盘。而InnoDB中使用的 redo log 和 undo log,它们是分开存储的。
redo log在内存中有log buffer,在磁盘对应ib_logfile文件。而undo log是记录在表空间ibd文件中的,InnoDB为undo log会生成undo页,对undo log本身的操作(比如向undo log插入一条记录),也会记录redo log,因此undo log并不需要马上落盘。而 redo log 则通常会分配一块连续的磁盘空间,然后先写到log buffer,并每秒刷一次磁盘。
redo log 必须在数据落盘前先落盘(Write Ahead Log),从而保证数据持久性和一致性。而数据本身的修改可以先驻留在内存缓冲池中,再根据特定的策略定期刷到磁盘。
2.InnoDB 磁盘上的结构
表空间:
分为系统表空间(MySQL 目录的 ibdata1 文件),临时表空间,常规表空间,Undo 表空间以及 file-per-table 表空间(MySQL5.7默认打开file_per_table 配置)。
系统表空间又包括了InnoDB数据字典,双写缓冲区(Doublewrite Buffer),修改缓存(Change Buffer),Undo日志等。
Redo日志:
存储的就是 Log Buffer 刷到磁盘的数据。

